Who am I?
I'm a data scientist, who's interested in finding Big Data proxy measures of various social and biological events, currently finishing up my PhD. I've listed some of the projects I've worked on during my grad school career below.
Big Data Analytics
I've gotten access to very large datasets of Tweets. The smallest was a set of 50 thousand Tweets from users that shared their medical records with us. The synthesis of these disparate datasources allowed us to build automated diagnostic systems. The largest dataset consists of over 2.5 Billion Tweets with precise geo-spatial information. This dataset has been used for many things such as studying spreading processes and out performing Google Flu Trends on "nowcasting" disease rates.
I've also worked on specialized datasets about topics ranging from AIDS to the Boston Marathon Bombing.


Crowdbreaks
CrowdBreaks is a visualizer of trends of disease Tweets based on a given location. This is similar to Google Flu Trends but with Twitter data and a larger set of diseases measured.
I mainly worked on the backend of this project, implementing the data collectors and processors along with various forms of caching and optimization to allow for almost immediate responses to user queries.
Fractal Analysis at the Santa Fe Institute
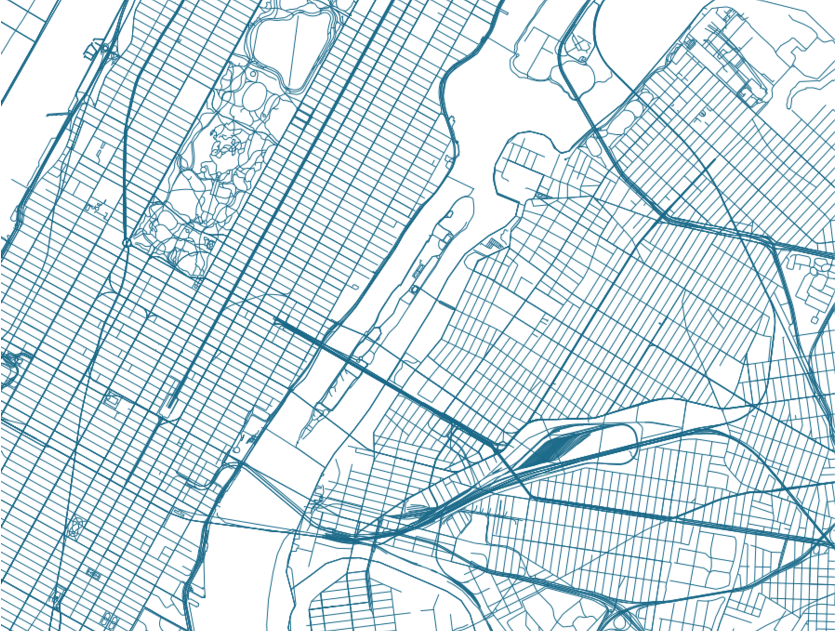
I had the pleasure of being part of the Santa Fe Institute's Complex Systems Summer School. While there, we developed models of city growth based on the fractal dimension of the city's transport network. For example, the transport networks of Manhattan, Queens and Central Park show different levels of order which we hypothesized corresponded with various social factors.
We studied select cities from each continent and found differences in the way the cities had grown. Additionally, I implemented a map-reduce version of our fractal dimension model to process the entire world's transport systems (provided by Open Street Maps).
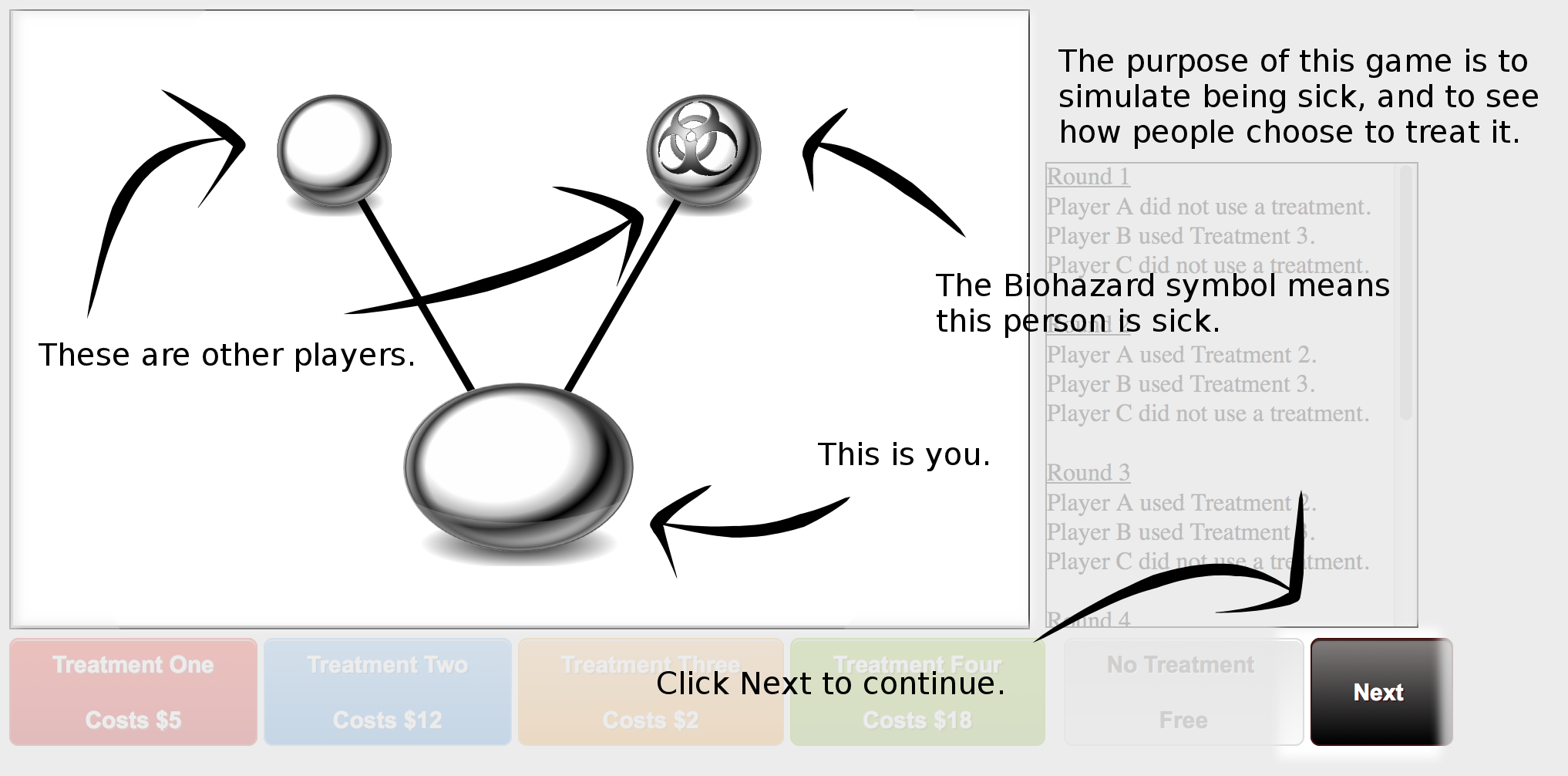
Online Experiments
I've prototyped a few online psychology experiments to be run through Amazon Turk, however the project was never completed. For example, the game shown (with tutorial overlay) tests if a person is able to determine the "best" treatment for a disease by observing the effects it had on her health along with what neighbors on the network are doing. These experiments were implemented in HTML5, Javascript, PHP and MySQL.